iOS Uygulaması Cold Start İyileştirmeleri, Karpathy Autoresearch, 117 Experiment ve 5 Frontier ModelTurkish
@karpathy geçtiğimiz günlerde oldukça ilginç bir konsept tanıttı. Bir AI modeline araştırma döngüsü kurduruyor, modele deney tasarlattırıyor, deneyi çalıştırtıyor, sonucu ölçtürüyor ve bir sonraki hipotezi ürettiriyor. Buna autoresearch diyor.
Andrej Karpathy (@karpathy) — 7 Mart 2026
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code.
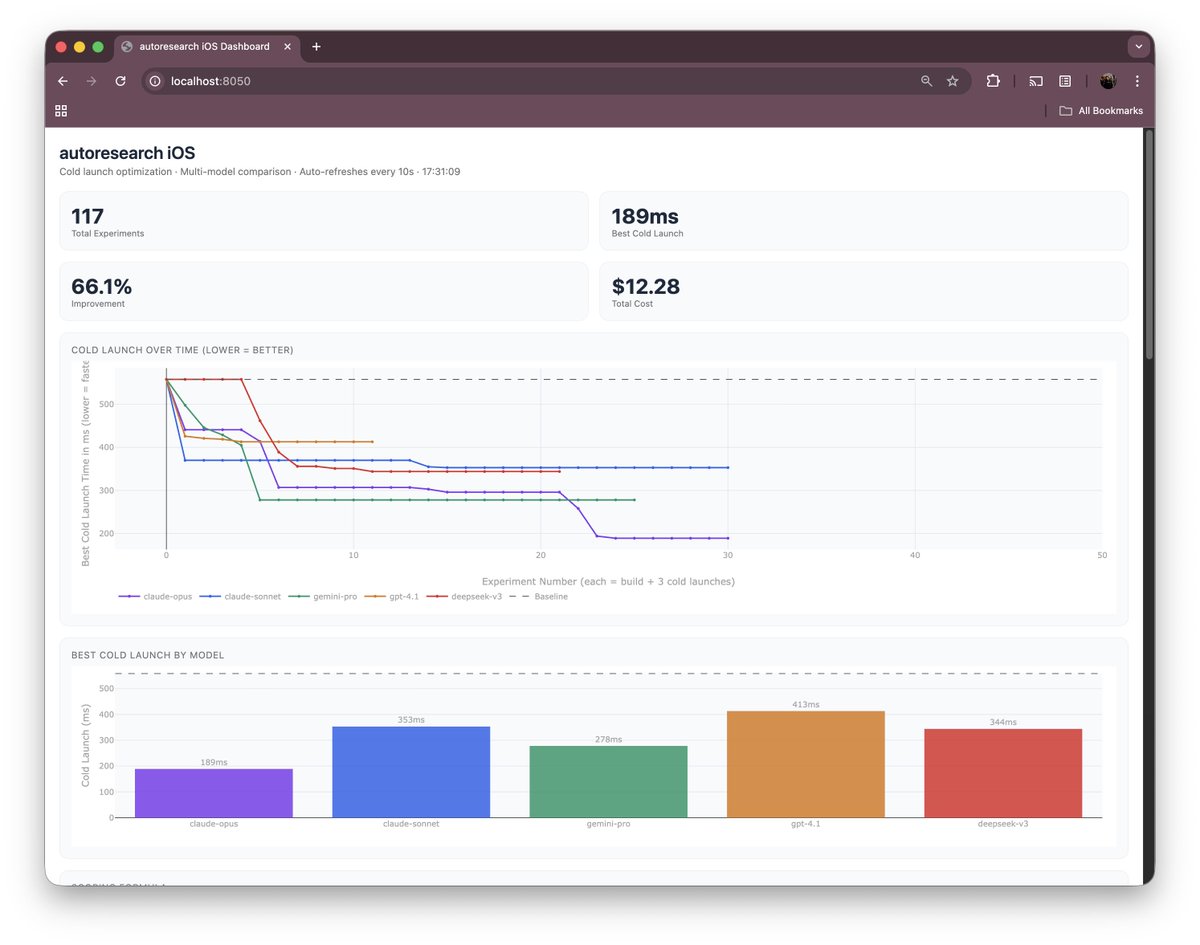
Ben de bu pattern'i görünce iOS geliştirmeye uyarlamayı denemek istedim. Middle Earth Explorer adlı App Store'da yayında olan uygulamam üzerinde 5 frontier AI modelini yaklaşık 117 deney boyunca birbirleriyle yarıştırdım. Bu fikir üzerine düşünürken en temelde, hangi model en iyi cold launch optimizasyonunu bulabilir diye merak ediyordum. Sonuç olarak uygulamanın cold launch süresini 558 milisaniyeden ~189-200 milisaniyeye indirmeyi başardım diyebilirim. Bu yüzde 66'lık bir iyileşmeye ve $12.28'lık bir toplam maliyete karşılık geldi. Ortaya çıkan süreç hem teknik hem de metodolojik açıdan oldukça öğretici oldu diye düşünüyorum.
Problemi biraz açmam gerekirse, Middle Earth Explorer, App Store'da yayında olan interaktif bir Yüzüklerin Efendisi harita uygulaması. Uygulamanın SwiftData katmanında 11 tane entity type bulunuyor ve LoreDataSeeder uygulamanın ilk açılışında 1600'den fazla kaydı bundled JSON dosyalarından SwiftData'ya yüklüyor. Uygulama içerisinde 51 lokasyon, 90'dan fazla tarihsel olay ve 43 farklı dil desteği mevcut. Dependency injection tarafında Swinject gibi ağır framework'ler kullanmak yerine 70 satırlık NSLock tabanlı protocol-driven bir ServiceProvider yazmayı tercih ettim. Basit ve temiz bir çözüm oldu ancak tüm bu katmanlar bir araya gelince launch path ciddi şekilde şişmeye başlıyordu. ModelContainer 11 entity type için initialize oluyor, 5 tab eager olarak ayağa kalkıyor ve analytics SDK'ları launch sırasında initialize ediliyordu. Bunların hepsi üst üste binince cold launch süresi 558 milisaniyeye kadar çıkıyordu.
Yöntem: Karpathy Autoresearch'ü iOS'a Uyarlamak
Karpathy autoresearch konseptini aslında LLM eğitimi için tasarlamıştı. Modeline prepare.py ile veri hazırlatıyor, train.py ile eğitimi çalıştırtıyor ve val_bpb metriğiyle sonucu ölçüyordu. Bu döngüyü iOS toolchain'ine çevirirken üç kritik adaptasyon yapmam gerekti.
- Birincisi, prepare.py yerine xcodebuild ve xcrun simctl ile bir build-measure harness'ı oluşturdum ve her deneyde clean build sonrası simulator üzerinde cold launch ölçümü yapmak oldu
- İkincisi, val_bpb metriğini cold_launch_ms ile değiştirdim ve simctl'den gelen timing marker verilerini parse etmek oldu.
- Üçüncüsü ise, program.md dosyasına iOS'a özgü constraint'leri yazarak, bu constraint'lerin
@MainActorkurallarını, SwiftData threading modelini ve SwiftUI lifecycle davranışlarını kapsamasını sağlamak oldu.
Beş modeli OpenRouter üzerinden tek bir API'den yönlendirdim ve her model kendi git branch'ında birbirinden tamamen izole bir şekilde çalıştı. Autoresearch forkumu, yani Autoresearch iOS'i, yarınki Açık Kaynak Pazartesi'nde Github profilimde paylaşacağım.
Sonuçlar: 5 Modelin Araştırmacı Kişilikleri
Bu deneylerin bence en ilginç bulgusu modellerin birbirinden farklı "araştırmacı kişilikleri" geliştirmesi oldu diye düşünüyorum. Karpathy, "hedef tek bir doktora öğrencisini taklit etmek değil, bir araştırma topluluğunu taklit etmek" demişti.
Andrej Karpathy (@karpathy) — 8 Mart 2026
The next step for autoresearch is that it has to be asynchronously massively collaborative for agents (think: SETI@home style). The goal is not to emulate a single PhD student, it's to emulate a research community of them.
Autoresearch iOS projesinde de, beş model gerçekten beş farklı araştırmacı gibi davranmaya başladı ve her birinin optimizasyon stratejisi diğerlerinden belirgin şekilde ayrıştı diyebilirim.
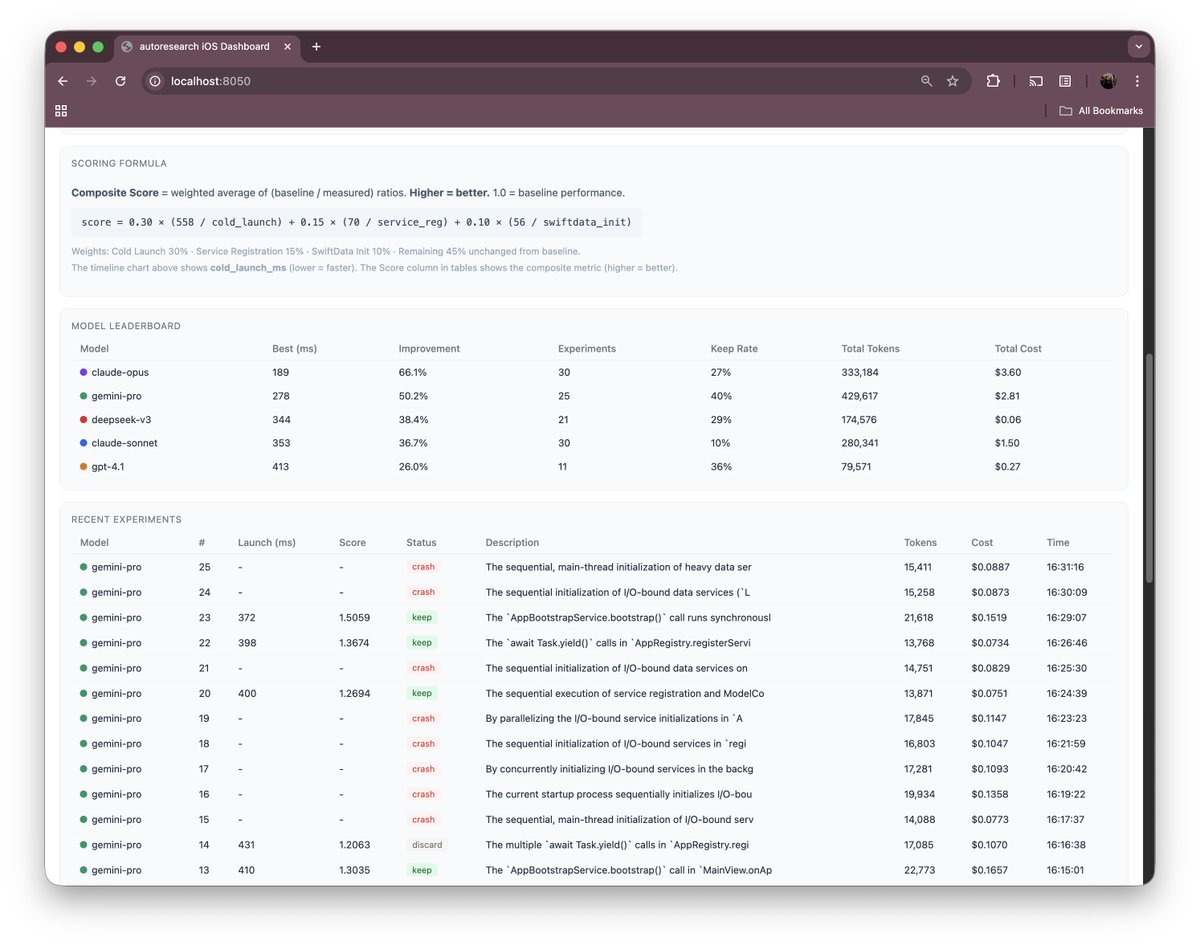
Opus 4.6 grubun "yüksek riskli araştırmacısı" olarak öne çıktı. Otuz deneyin sekizini başarıyla tuttu ve cold launch süresini 189 milisaniyeye kadar indirmeyi başardı. Bu yüzde 66'lık bir iyileşmeye karşılık geliyordu ve toplam $3.60 harcadı. Crash oranı sadece yüzde 7 seviyesinde kaldı. Opus diğer modellerin hiçbirinin dokunmadığı mimari katmanlarda breakthrough'lar keşfetti. Lazy tab construction ve sync ModelContainer gibi view hierarchy seviyesindeki değişiklikleri sadece Opus bulabildi ve bu değişiklikler en büyük performans kazanımlarını sağladı.
Gemini 2.5 Pro takımın "kararlı tırmanıcısı" oldu diyebilirim. İlk turda max_tokens ayarındaki bir hata yüzünden tüm deneyleri crash etti ve bu tamamen benim hatamdı. 16K token fix'ini uyguladıktan sonra yirmi beş deneyin yedisini tuttu ve cold launch süresini 498 milisaniyeden 278 milisaniyeye kadar her adımda istikrarlı bir şekilde düşürdü. Bu yüzde 50'lik bir iyileşmeye karşılık geliyordu ve toplam $2.25 harcadı. Gemini'nin en dikkat çekici özelliği hiç regresyon yapmadan sürekli ilerleme kaydetmesi oldu.
DeepSeek V3 bu yarışın "bütçe şampiyonu" olarak çok çarpıcı bir performans sergiledi. Yirmi bir deneyin altısını tuttu ve cold launch süresini 344 milisaniyeye indirmeyi başardı. Bu yüzde 38'lik bir iyileşmeye karşılık geliyordu ve toplam maliyeti sadece $0.06 olarak gerçekleşti. Bu rakam Opus'un harcadığı maliyetin yüzde 1.7'sine karşılık geliyordu. DeepSeek mimari değişiklik yapmak yerine servis katmanı optimizasyonlarına odaklanmayı tercih etti ve bu stratejiyle oldukça verimli sonuçlar elde etti.
Sonnet 4.6 grubun "temkinli mühendisi" gibi çalıştı diyebilirim. Otuz deneyin sadece üçünü tutabildi ve cold launch süresini 353 milisaniyede durdurdu. Bu yüzde 37'lik bir iyileşme sağlamıştı ve toplam $1.50 harcadı. Ancak yüzde 30'luk bir crash oranı yaşadı ve view hierarchy katmanına hiç dokunmadan sadece servis katmanında kalmayı tercih etti.
GPT-4.1 bu deneylerin "inatçı cerrahı" olarak tanımlanabilir diye düşünüyorum. İlk dört deneyinde yüzde 100 başarı oranıyla 413 milisaniyeye ulaştı ve sadece $0.27 harcadı. Ancak sonraki yedi ardışık deneyde aynı timing marker kaldırma hatasını tekrar tekrar denedi. Ölçüm altyapımızdaki timing marker'ları gereksiz kod olarak değerlendirdi ve her seferinde silmeye çalıştı. Önceki hatalarından ders çıkaramadı ve farklı bir strateji denemeye pivot edemedi. Bu durum modelin context window'unda hata geri bildirimini yeterince işleyememesinden kaynaklanıyor olabilir. Ama diğer modeller bunun etrafından dolanmayı başarabildiği için adil bir kıyaslama yapmak adına GPT-4.1'e takıldığı bu noktada bir ipucu vermemeyi seçtim.
Detaylı Analiz: Opus'un 3 Breakthrough Deneyi
Opus'un sekiz KEEP deneyini Swift runtime seviyesinde incelediğimde üç kritik kırılma noktası dikkatimi çekti.
- Birinci deneyde Opus paralel ModelContainer oluşturma stratejisini denedi ve cold launch süresini 558'den 441 milisaniyeye düşürdü. Bu deneyde ModelContainer.init(for:configurations:) çağrısını Task.detached içine alarak main thread'i serbest bırakmayı başardı ve 117 milisaniyelik bir kazanım sağladı.
- Altıncı deneyde lazy tab construction yaklaşımını keşfetti ve cold launch süresini 414'ten 307 milisaniyeye indirdi. SwiftUI'da TabView içerisindeki beş tab'ın her biri NavigationStack, ScrollView ve MapView içeriyordu ve bunların hepsi launch sırasında eager olarak initialize ediliyordu. Opus sadece aktif tab'ı render edip diğerlerini kullanıcı ilk kez o tab'a geçtiğinde oluşturmayı önerdi ve bu değişiklik tek seferde 107 milisaniyelik bir performans farkı ortaya koydu.
- Yirmi üçüncü deneyde sync ModelContainer in init() stratejisini uygulayarak cold launch süresini 258'den 194 milisaniyeye düşürdü. Bu deneyde Opus ModelContainer.init()'i App.init() içinde senkron olarak çağırarak async/await scheduling overhead'ini tamamen ortadan kaldırdı ve 64 milisaniyelik bir kazanım daha ekledi.
Bu üç deney tek başına toplam iyileşmenin yüzde 78'ini oluşturuyordu. Karpathy kendi LLM deneylerinde 700 deneyden 20 optimizasyon bulmuştu ve bu yüzde 2.9'luk bir hit rate'e karşılık geliyordu.
Andrej Karpathy (@karpathy) — 9 Mart 2026
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models.
Opus ise 30 deneyden 8 optimizasyon buldu ve yüzde 27'lik bir hit rate yakaladı. iOS codebase'inin LLM eğitim koduna göre daha dar bir optimizasyon uzayına sahip olması bu farkı kısmen açıklıyor olabilir ama oranın bu kadar yüksek çıkması yine de dikkat çekici diye düşünüyorum.
Maliyet ve Verimlilik
Toplam $12.28'lik bütçenin modeller arasındaki dağılımı aslında bir model seçim rehberi niteliği taşıyor diyebilirim. DeepSeek Opus'un toplam maliyetinin yüzde 1.7'siyle Sonnet seviyesinde bir iyileştirme sağlamayı başardı. Opus en pahalı model olarak en derin sonucu buldu ve harcadığının önemli bir kısmı crash eden deneylere gitse de lazy tab construction ve sync ModelContainer gibi mimari breakthrough'lar sadece ondan çıkabildi. GPT-4.1'in hikayesi ise ayrı bir mühendislik dersi barındırıyordu. İlk dört deneyinde son derece verimli çalıştı ve o noktada yarışın en yüksek başarı oranına sahip modeliydi. Ancak sonraki yedi ardışık deneyde COLD_LAUNCH_START ve COLD_LAUNCH_END timing marker'larını gereksiz kod olarak değerlendirip silmeye çalıştı ve uygulama ölçümsüz kalınca crash etti. Model bir sonraki deneyde tam olarak aynı değişikliği tekrar denedi ve bu döngüden çıkamadı. Bu deneyimden çıkardığım sonuç şu oldu, bir modelin ilk deneylerdeki başarı oranı uzun vadeli performansını garanti etmiyor ve pivot yapabilme kapasitesi en az ham zeka kadar önemli olabiliyor.
Teknik Çıkarımlar
Bu deneylerin teknik tarafından da bahsetmem gerekiyor çünkü 117 deneyden herkesin kendi projelerinde uygulayabileceği somut iOS optimizasyon pattern'leri ortaya çıktı.
- Task.yield() çağrılarının launch path'te fayda yerine zarar verebileceğini gördüm. Cooperative scheduling amacıyla iyi niyetle eklenen bu çağrılar aslında launch sırasında gereksiz context switch maliyeti yaratıyordu.
- Lazy tab construction yaklaşımının SwiftUI'da çok ciddi bir performans farkı yarattığını gördüm ve beş tab'ı eager olarak render etmek yerine sadece aktif tab'ı oluşturmak tek seferde 107 milisaniye kazandırıyordu.
- ModelContainer.init()'i async'ten sync'e geçirmenin scheduling overhead'ini tamamen kaldırdığını gözlemledim ve App.init() içinde senkron çağırmak async/await'in cooperative thread pool round-trip maliyetini ortadan kaldırıyordu.
- AnalyticsService, Sentry ve TelemetryDeck gibi SDK'ları launch sırasında değil post-interactive aşamada initialize etmenin önemini bir kez daha doğruladım.
- nonisolated(unsafe) static let pattern'inin immutable data için Swift 6 strict concurrency altında hem güvenli hem de performanslı bir çözüm sunduğunu teyit ettim.
Bu pattern'lerin her birini tek tek manuel olarak bulmak elbette mümkündü, ama beş modelin paralel çalışması hepsini bir arada ve çok daha hızlı bir şekilde ortaya çıkardı diyebilirim.
Orta Dünya Haritası uygulamasının iki versiyonunu da tamamen Claude CLI kullanarak geliştirdiğim için, geliştirme sürecinde verimsiz olarak çalışan çok fazla koda denk geldim. Bu Autoresearch iOS çalışmasıyla, agentic mühendislik ile mobil uygulama geliştirme süreçlerine bir "skill" olarak eklenebilecek bir optimizasyon aşaması eklenebileceğini düşünüyorum. Tüm optimizasyon pipeline'ını Claude Marketplace'te bir skill olarak da yayınlamayı düşünüyorum ve böylece kendi iOS uygulamanızda aynı deney döngüsünü de çalıştırabilirsiniz diye düşünüyorum.
Açık Kaynak Pazartesi'si kapsamında Autoresearch iOS'in kaynak kodlarını yarın Github profilimde yayınlayacağım.
Bu süreçte benim için en değerli öğrenme, farklı modellerin gerçekten farklı düşündüğünü ve farklı mimari katmanlarda arama yaptığını görmek oldu diye düşünüyorum. Tek bir modele 117 deney yaptırmak yerine beş modele bağımsız araştırma yaptırmak çok daha zengin ve çok daha öğretici sonuçlar ortaya koyuyor ve modellerin karakteristiğini iOS mühendisliği özelinde gösteriyor.